
As a High-Performance Computing (HPC) expert, I am part of the ByteNN team at ByteDance in China, focusing on full-stack optimization of deep learning algorithms, including model optimization and GPU-based inference acceleration.
in China, focusing on full-stack optimization of deep learning algorithms, including model optimization and GPU-based inference acceleration.
I graduated from School Of Optical and Electronic Information, Huazhong University of Science & Technology (华中科技大学光电学院) with a bachelor’s degree and from the ISEE, Zhejiang University (浙江大学信电学院) with a master’s degree. My research interest includes AutoML, High-Performance Computing (HPC) and System Algorithm co-design. I have published 7+ papers at the top international AI conferences such as AAAI, ACM-MM, CVPR.
I am now leading model optimization efforts at ByteNN team, driving collaborative optimizations between the inference engine and model architecture to reduce cloud inference costs for LLM and Diffusion models, while advancing the deployment of AIGC models on edge devices. My current research interests include:
- Lightweight and Efficient Backbone Model, including compact architectures like small-scale VAEs, SDXL,and LLMs.
- Quantization-based Inference Acceleration tailored for diverse hardware platforms and computational tasks.
- Sparsity-driven Inference Acceleration through systematic model compression and sparse computation optimization.
- Cache Reuse Optimization, Distributed Parallel Optimization, and Communication Optimization.
If you are seeking any form of academic cooperation, please feel free to email me at liusongwei.zju@bytedance.com. We are hiring interns!
🔥 News
- 2024.12: 🎉 One paper is accepted by AAAI 2025
- 2023.07: 🎉 One papers is accepted by ACM-MM 2023
- 2022.05: 🎉 One papers is accepted by CVPR 2022
- 2022.03: 🎉 Won the Championship 🏆 at the NTIRE 2022 Challenge on Efficient Super-Resolution
- 2021.05: I join ByteDance as a Multimedia Algorithm Engineer in Shanghai, China!
📝 Publications
📚 System Algorithm Co-design
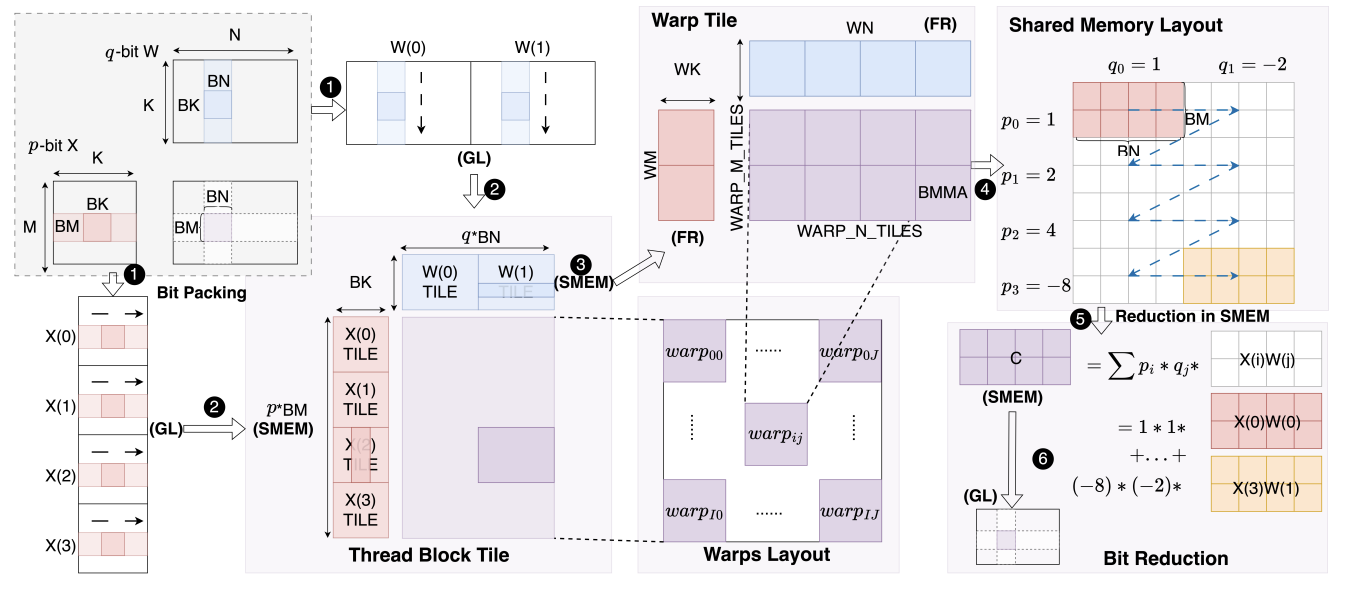
ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models
Chao Zeng *, Songwei Liu*, Yusheng Xie*, Hong Liu, Xiaojian Wang,
Miao Wei, Shu Yang, Fangmin Chen, Xing Mei †
Project |

- 🚀 ABQ-LLM breaks quantization limits: Run LLMs at ANY bit-width you want, with REAL speedup!
- Academic Impact: It introduces hardware-aware dynamic quantization, enabling latency-optimal bit allocation across transformer layers without retraining.
- Industry Impact: It achieves a 1.6x inference speedup and 2.7x memory compression ratio compared to the industry’s state-of-the-art SmoothQuant framework, with its kernel performance significantly surpassing CUTLASS-accelerated operators.
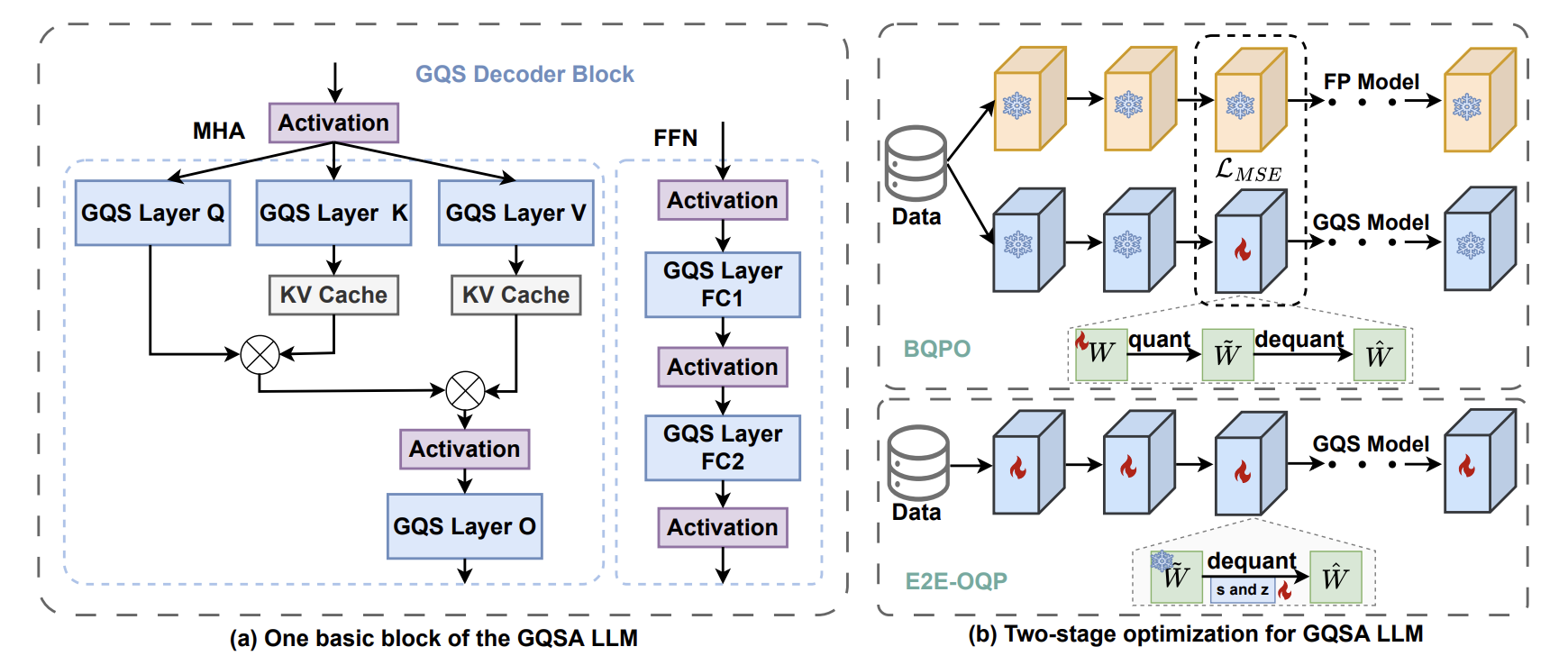
GQSA: Group Quantization and Sparsity for Accelerating Large Language Model Inference
Chao Zeng*, Songwei Liu*, Shu Yang, Fangmin Chen †, Xing Mei, Lean Fu
-
🚀 GQSA explores a group sparsity pattern beyond the conventional 2:4 sparsity, achieving a better trade-off between accuracy and speed through a combination of algorithmlevel optimizations and a customized software engine.
-
GQSA offers several advantages over the 2:4 sparsity technique, such as Flexible and Adjustable Sparsity Rate, Higher Weight Compression Rate, Enhanced Compatibility with Various Quantization Methods.
Arxiv 2023SparseByteNN: A Novel Mobile Inference Acceleration Framework Based on Fine-Grained Group Sparsity, Songwei Liu*, Haitao Xu, Yuyang Xu, Shuai Wang, Jiashi Li, Chenqian Yan, et al.
📚 Model Compression

Residual Local Feature Network for Efficient Super-Resolution
Fangyuan Kong*, Mingxi Li*, Songwei Liu*, Ding Liu, Jingwen He, Yang Bai, Fangmin Chen, Lean Fu
Project |

- 🚀 RLFN achieves state-of-the-art (SOTA) performance in lightweight super-resolution through innovative architectural design, advanced training strategies, and efficient model compression techniques!
- Academic Impact: It has emerged as a foundational baseline in the Efficient Super-Resolution (ESR) domain, driving advancements across the field.
- Industry Impact: It serves as the official baseline model for the NITRE 2023 competition and is applied to multiple product lines of ByteDance.
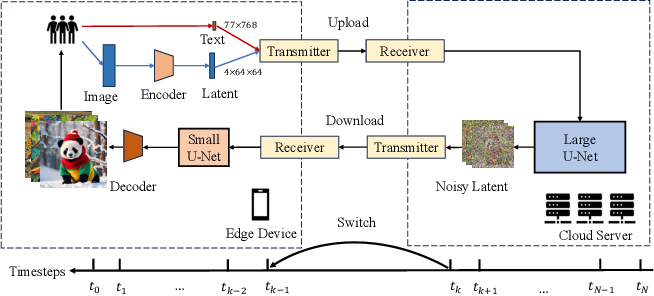
Hybrid SD: Edge-Cloud Collaborative Inference for Stable Diffusion Models
Chenqian Yan*, Songwei Liu*, Hongjian Liu*, Xurui Peng, Xiaojian Wang, Fangmin Chen, Lean Fu, Xing Mei.
Project | 
- 🚀 Hybrid-SD has launched the industry’s most performant lightweight models: VAE, SD1.5, and SDXL. Now available for deployment!
-
Arxiv 2024FoldGPT: Simple and Effective Large Language Model CompressionScheme, Songwei Liu* Chao Zeng*, Lianqiang Li, Chenqian Yan, Lean Fu, Xing Mei, Fangmin Chen †. -
ACM-MM 2023Unfolding once is enough: A deployment-friendly transformer unit for super-resolution, Y Liu, H Dong, B Liang, Songwei Liu, Q Dong, K Chen, F Chen, L Fu, F Wang. -
Arxiv 2021Mixsearch: Searching for domain generalized medical image segmentation architectures, L Liu, Z Wen, Songwei Liu, HY Zhou, H Zhu, W Xie, L Shen, K Ma, Y Zheng. -
ICCA 2019Binary convolutional neural network with high accuracy and compression rate, Songwei Liu, Hongwei Zhu.
🎖 Projects and Skills
- Programming Language: Python, C++, CUDA C/PTX
- Technical Expertise: Expert in low-level kernel optimization
- Deep optimization of core operators using MMA/WMMA instructions and PTX assembly-level tuning
- Quantized GEMM implementation for both compute-intensive and memory-bound scenarios
- Proficient with CUDA acceleration libraries: CUTLASS, TensorRT, FastTransformer, and Triton
- Key Project Experience:
- Responsible for Doubao multi-modal model inference optimization;
- ByteNN-LLM inference engine architecture design and CUDA backend implementation;
- Core developer of the Lighten inference engine.
📖 Educations
- 2018.09 - 2021.03, Master, Zhejiang University, Hangzhou,Zhejiang.
- 2014.09 - 2018.06, Bachelor, Huazhong University of Science and Technology, Wuhan,Hubei.
- 2011.09 - 2014.06, Shangqiu No.1 Senior Middle School, Shangqiu,Henan.
💬 Invited Talks
- 2024.11, Quantization and Sparsity Optimization for AIGC Models – Public Presentation at ML-Summit 2024
💻 Internships
- 2020.06 - 2020.09, HikVision, Research Center, Hangzhou.
- 2019.08 - 2020.06, TenCent, JARVIS Lab, Network Architecture Search, ShenZhen.
- 2019.04 - 2019.07, FaBu, Autonomous driving, Model Compression, Hangzhou.