
Songwei Liu
I build efficient LLM/AIGC inference systems for edge-cloud computing platforms.
Songwei Liu is an MLSys optimization expert in the Data-AML Heterogeneous Hardware team at ByteDance. He obtained his bachelor's degree from Huazhong University of Science & Technology, and his master's degree from Zhejiang University.
His research focuses on efficient model architecture design and foundation model training, algorithm/model optimization and software-hardware co-optimization, and inference optimization for multi-end heterogeneous platforms.
Efficient AIGC
Quantization/sparsity-driven software-hardware co-optimization, cache/MoE-token/resolution compression, and efficient foundation model training.
Efficient LLM
Quantized and sparse inference/training, speculative decoding, long-context acceleration, and deployment-oriented compression.
Heterogeneous Inference
Long-context inference systems, agentic workload serving, KVCache systems, and multi-end edge-cloud deployment.
At ByteDance, Songwei Liu leads a model optimization team that provides post-training optimization, algorithm/model optimization, and software-hardware co-optimization for Seedance, Seedream, and Volcengine open-source LLM/VLM models, substantially reducing cloud inference costs for these model families.
His academic work spans ICML, ICLR, ACL, AAAI, IJCNLP-AACL, ACM-MM, CVPRW, and Nature Communications, with a focus on practical efficiency methods that transfer from papers to production systems.
He is interested in academic cooperation around efficient AIGC/LLM systems, foundation model optimization, and software-hardware co-design. His team regularly recruits interns; interested candidates can apply through the ByteDance referral link or contact him by email.
News
MotionCache is accepted by ICML 2026.
TCEC is accepted by ICML 2026 Spotlight + Oral, Top 0.7%.
S2O is accepted by ACL 2026 Oral.
DreamLite is accepted by ECCV 2026; it is a SOTA on-device unified image generation and editing model.
GQSA is published at IJCNLP-AACL 2025 and receives Best Paper Honorable Mention.
ERTACache is accepted by ICLR 2026.
ABQ-LLM is accepted by AAAI 2025.
UOE is accepted by ACM-MM 2023.
RLFN is accepted by CVPRW 2022.
RLFN won the Championship at NTIRE 2022 Efficient Super-Resolution Challenge.
Songwei Liu joined ByteDance as an AI Infra Engineer in Shanghai, China.
Selected Publications
Google Scholar snapshot on 2026-06-06: 17 publications, 562 citations, h-index 9.

DreamLite: A Lightweight On-Device Unified Model for Image Generation and Editing
Status: ECCV 2026 · Topic: on-device image generation and editing
Presents a SOTA on-device unified model for image generation and editing, targeting practical mobile deployment with strong quality-efficiency trade-offs.

TCEC: Error Propagation Mechanisms and Compensation Strategies for Quantized Diffusion
Status: ICML 2026 Spotlight + Oral, Top 0.7% · Topic: diffusion quantization
Studies how quantization errors propagate across diffusion timesteps and proposes timestep-aware compensation strategies for efficient low-bit generation.

Motion-Aware Caching for Efficient Autoregressive Video Generation
Status: ICML 2026 · Topic: video generation cache reuse
Uses motion-aware token update scheduling to reduce redundant computation in autoregressive video generation while preserving temporal quality.

S2O: Early Stopping for Sparse Attention via Online Permutation
Status: ACL 2026 Oral · Role: co-first author; Project Lead (LD) · * equal contribution
Introduces online permutation and early-stopping mechanisms for sparse attention, reducing attention computation while keeping model quality stable.

ERTACache: Error Rectification and Timesteps Adjustment for Efficient Diffusion
Status: ICLR 2026 · Role: co-corresponding author · † co-corresponding author
Combines timestep adjustment with online error rectification to make diffusion cache reuse more robust under aggressive acceleration settings.

Seedance 1.5 Pro: A Native Audio-Visual Joint Generation Foundation Model
Status: arXiv 2025 · Topic: audio-visual generation foundation model
Reports a native audio-visual joint generation foundation model and the production-oriented optimization stack behind efficient deployment.
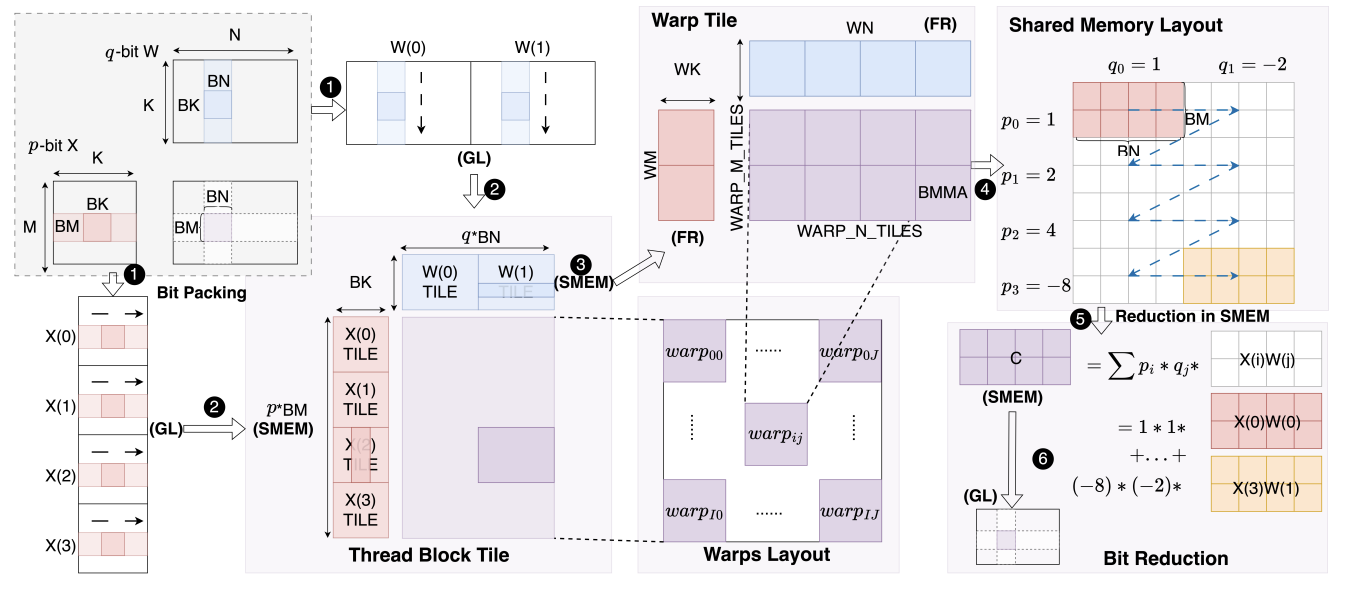
ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models
Status: AAAI 2025 · Role: co-first author · * equal contribution
Enables arbitrary-bit LLM inference acceleration through hardware-aware dynamic quantization and latency-optimal bit allocation.
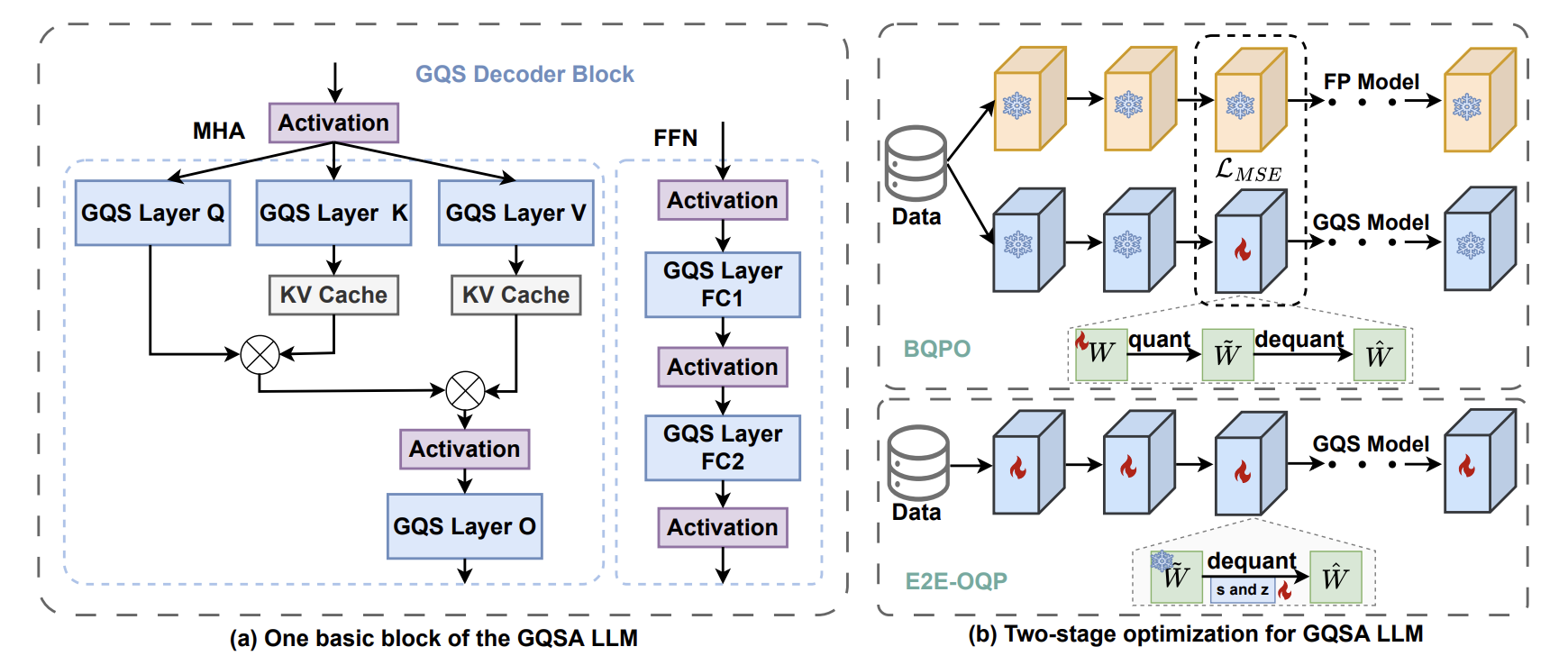
GQSA: Group Quantization and Sparsity for Accelerating Large Language Model Inference
Status: IJCNLP-AACL 2025 · Award: Best Paper Honorable Mention · * equal contribution
Explores group sparsity beyond conventional 2:4 sparsity, combining algorithm-level sparsification with customized inference kernels.

Lightweight Error-Tolerant Edge Detection Using Memristor-Enabled Stochastic Computing
Status: Nature Communications 2025 · Topic: efficient vision computing
Demonstrates lightweight, error-tolerant edge detection by combining stochastic computing with memristor-enabled hardware characteristics.
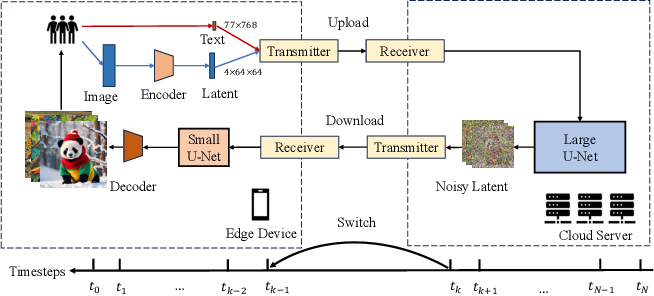
Hybrid SD: Edge-Cloud Collaborative Inference for Stable Diffusion Models
Status: arXiv 2024 · Role: co-first author · * equal contribution
Builds an edge-cloud collaborative inference framework for Stable Diffusion, balancing mobile latency, cloud quality, and deployment cost.
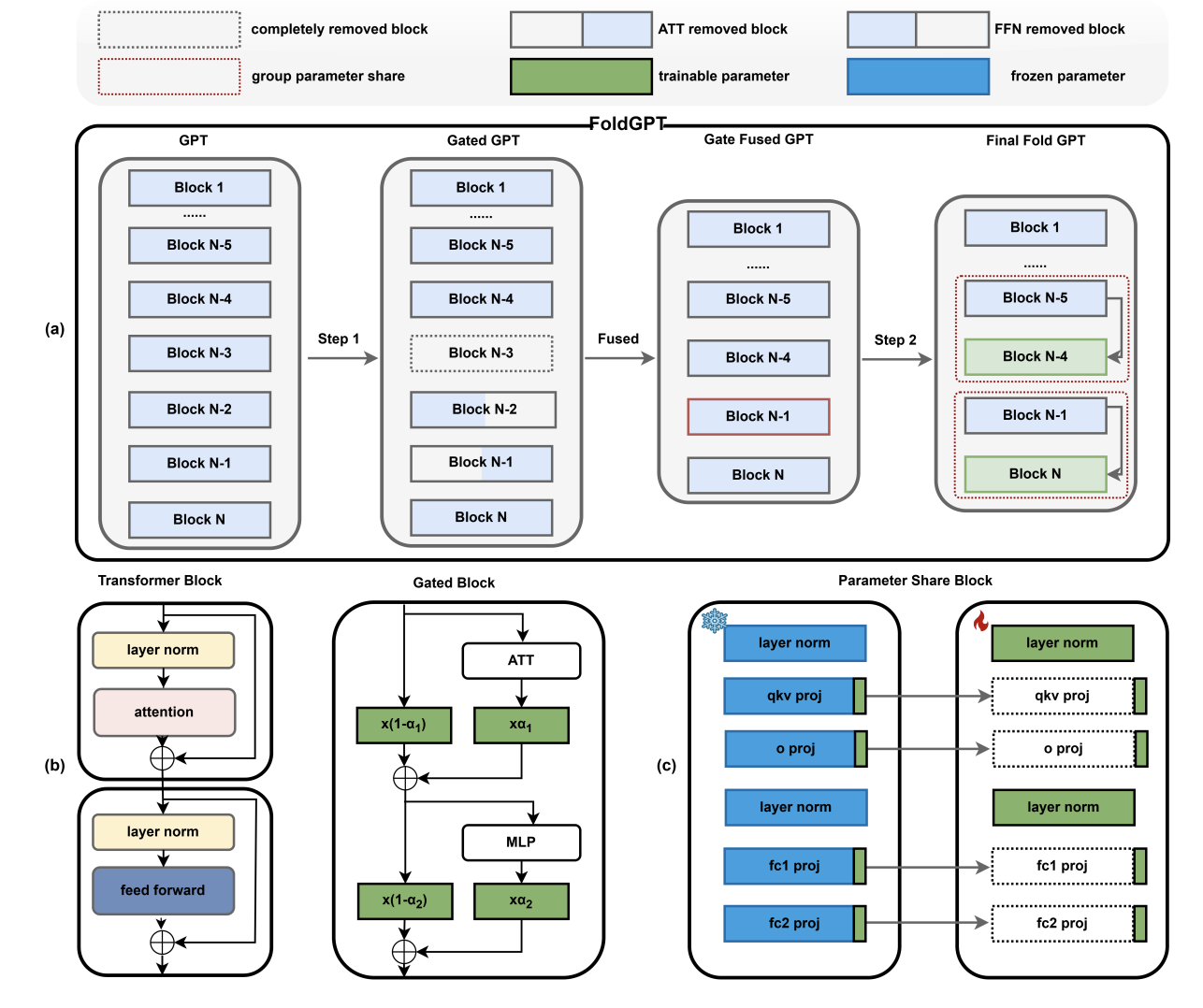
FoldGPT: Simple and Effective Large Language Model Compression Scheme
Status: arXiv 2024 · Role: co-first author · * equal contribution
Provides a simple LLM compression scheme that folds model structure and parameters for efficient inference-oriented deployment.
Unfolding Once is Enough: A Deployment-Friendly Transformer Unit for Super-Resolution
Status: ACM-MM 2023 · Topic: deployment-friendly super-resolution
Designs a practical transformer unit for super-resolution that improves deployment efficiency while retaining reconstruction quality.

SparseByteNN: A Novel Mobile Inference Acceleration Framework Based on Fine-Grained Group Sparsity
Status: arXiv 2023 · Role: co-first author · * equal contribution
Introduces fine-grained group sparsity and a mobile inference acceleration framework for efficient on-device neural network deployment.

Residual Local Feature Network for Efficient Super-Resolution
Status: CVPRW 2022 · Role: co-first author · * equal contribution
Establishes a lightweight super-resolution baseline with strong quality-efficiency trade-offs and practical production deployment value.

NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
Status: CVPRW 2022 · Topic: efficient super-resolution challenge
Summarizes NTIRE 2022 efficient super-resolution methods and results, including the champion solution adopted as a practical ESR baseline.

MixSearch: Searching for Domain Generalized Medical Image Segmentation Architectures
Status: arXiv 2021 · Topic: medical image segmentation NAS
Searches architectures for domain-generalized medical image segmentation, improving robustness across dataset and domain shifts.

Binary Convolutional Neural Network with High Accuracy and Compression Rate
Status: ICCA 2019 · Topic: binary neural network compression
Studies high-compression binary convolutional networks and accuracy-preserving model compression for efficient inference.
Projects
Production-facing optimization work across AIGC system-algorithm co-design, model optimization, and edge-cloud inference systems.
Seedance / Seedream Inference and Training Optimization
Led algorithm optimization and software-hardware co-optimization for Seedance 1.0-2.0 and Seedream 4.0-5.0 on heterogeneous NPU/GPU hardware, covering non-NVIDIA backends.
Designed quantization/sparsity algorithms and operator stacks compatible with dynamic LoRA and distributed FSDP/TP/EP architectures, supporting Seedance and Seedream production migrations from full BF16 to INT8/FP8, and then further to full INT4/MXFP4 online deployment.
Designed hierarchical quantized training strategies and rebuilt the FSDP communication path around quantized weights to reduce distributed training communication overhead. This was the first production deployment of quantized training for ByteDance generative models.
Cache/MoE/Token Compression and Distillation
Developed cache reuse methods for diffusion and autoregressive generation, including timestep correction, offline policy search, online error rectification, and motion-aware token update scheduling.
Built lightweight model optimization pipelines for DynamicRes, 2D/3D VAE compression, and distillation-oriented generative model deployment across image/video generation scenarios.
The model-compression capability matrix further accelerates low-NFE step-distilled models by 35% to 50% at inference time.
Lightweight Foundation Models, Extreme Compression, and Efficient Engines
Lightweight foundation models: developed SOTA lightweight LLM/VLM foundation models that are scheduled for open source release, the lightweight unified generation-editing model DreamLite, and the edge-cloud inference framework HybridSD.
Extreme model compression: built ultra-low-bit quantization solutions for edge-side NPU/GPU platforms, achieving lossless inference at an equivalent 2-bit precision while supporting products used by billions of users.
Inference engine: participated in designing the ByteNN-LLM on-device LLM/AIGC inference engine architecture, where a 1+N on-device serving architecture enables a single foundation model to support multiple business needs, and delivered the industry's first PC-CUDA arbitrary-precision quantized inference solution.
Skills
Python, C++, CUDA C/PTX
System-algorithm co-design, model compression, PTQ/QAT, sparse and quantized kernels, cache reuse, distributed inference/training optimization.
vLLM, CUTLASS, Triton, distributed serving/training stacks, heterogeneous NPU/GPU deployment toolchains.
GEMM, Attention, Dense/Sparse operator tuning with MMA/WMMA and PTX assembly, quantized GEMM for compute- and memory-bound workloads.
Background
Master, Zhejiang University, Hangzhou, Zhejiang.
Bachelor, Huazhong University of Science and Technology, Wuhan, Hubei.
Shangqiu No.1 Senior Middle School, Shangqiu, Henan.
HikVision Research Center, Hangzhou.
Tencent JARVIS Research Center, network architecture search, Shenzhen.
FaBu, autonomous driving and model compression, Hangzhou.
Invited Talks
Quantization and Sparsity Optimization for AIGC Models
Public presentation at ML-Summit 2024.
Get in Touch
If you are seeking academic cooperation, invited talks, or technical discussion around efficient AIGC/LLM systems, the best way to reach Songwei Liu is via email.
Current Collaboration Interests
Open to research collaborations on efficient foundation model training, AIGC/LLM inference optimization, cache reuse, sparse/quantized computation, and software-hardware co-design.